Building ZeroPool: How I Made LLM Checkpoint Loading 3.8x Faster
The story of engineering a high-performance buffer pool in Rust after hitting unexpected bottlenecks with existing solutions.
The Problem Was Hiding in Plain Sight
I was building an io_uring-based LLM checkpoint loader for loading safetensors model files. The goal seemed straightforward: read model weights as fast as possible using Linux's newest async I/O interface. io_uring promised zero-copy, kernel-level efficiency, the architecture looked perfect on paper.
The initial approach was simple: allocate a buffer large enough for the entire safetensors file, then read it all at once.
// My initial approach: single large read
async fn load_checkpoint(path: &str) -> Result<Vec<u8>> {
let file = File::open(path).await?;
let metadata = file.metadata().await?;
// Allocate buffer for the entire file
let buffer = vec![0u8; metadata.len() as usize];
// Read all at once
let (result, buffer) = file.read_at(buffer, 0).await;
Ok(buffer)
}
But when I profiled my code, something was deeply wrong. Loading a GPT-2 checkpoint (around 350MB in safetensors format) took 200ms. The profiler revealed a shocking truth: 70% of that time was spent allocating that single massive buffer, not doing I/O. The io_uring ring was idle. The disk was barely being used. My program was trapped in malloc() and memset().
This is the moment every systems programmer dreads: your bottleneck isn't where you thought it was.
The Search for an Off-the-Shelf Solution
The fix seemed obvious, stop allocating new buffers every time. Reuse them. This is Computer Science 101, and surely the Rust ecosystem had already solved it?
I explored three popular libraries, each with their own fatal flaws.
Mempool: This library returns an immutable reference, but tokio-uring needs owned Vec<u8> that can cross await boundaries and be passed to the kernel. You cannot move an owned value out of a reference. Dead end.
Lifeguard: Better! It provides a smart pointer wrapper. But it doesn't implement Send or Sync, which means you cannot wrap it in Arc to share across async tasks. For a multi-threaded workload, this library was off the table.
Object-Pool: Thread-safe, shareable, but the implementation didn't deliver the throughput I needed for high-volume I/O workloads. Measurement showed it wasn't meeting performance targets.
Each library solved 80% of the problem. None of them solved my 20%.
Building Exactly What I Needed
At this point I had a choice: accept the limitations of existing solutions, or engineer the exact thing my workload required.
I chose to build. Here's what I needed:
- Owned
Vec<u8>buffers, not references, not smart pointers - Thread-safe sharing across async tasks
- Optimized for high-throughput I/O patterns
- Dead simple API: just
get()andput()
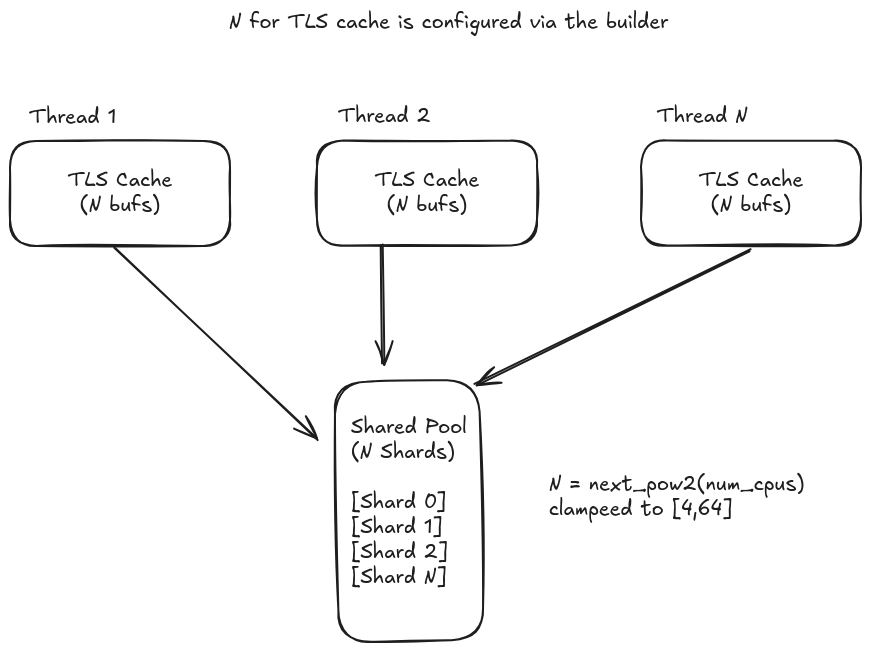
The architecture hinges on one key insight: most buffer requests can be satisfied from thread-local storage with zero contention and zero locks. When thread-local storage runs out, fall back to a sharded global pool.
This two-tier design resembles familiar memory management patterns, L1 cache hitting a majority of the time, with L2 handling misses. In practice, thread-local TLS satisfies majority of requests without ever acquiring a lock.
Why Sharding Prevents Bottlenecks
A single global Mutex<Vec<Vec<u8>>> would be a catastrophe. With eight threads hammering it, you'd spend more time waiting for locks than doing work.
Sharding solves this by distributing contention across multiple locks. But the initial round-robin approach left performance on the table. The breakthrough came with thread-local shard affinity: each thread consistently uses the same shard based on its thread ID.
// Thread-affinity shard selection (better cache locality!)
let shard_idx = hash(thread_id) & (num_shards - 1);
let shard = unsafe { shards.get_unchecked(shard_idx) }.lock();
This seemingly small change delivered 14-38% throughput improvements. Why? CPU cache locality. When a thread consistently accesses the same shard, that shard's data stays hot in the CPU's L3 cache. Round-robin scattered access across all shards, thrashing the cache.
Power-of-2 sharding enables bitwise AND instead of modulo division—single-cycle operation versus multi-cycle division. This matters when you're in a hot loop millions of times per second.
The Unsafe Optimization You're Probably Not Doing
When you write vec![0u8; 1024 * 1024], Rust allocates 1MB and writes zeros to every single byte. That's an entire megabyte traversing the memory bus. And here's the kicker: I'm about to overwrite it with file data anyway. Those zeros are discarded immediately.
This is where unsafe code becomes a tool rather than a curse:
let mut buffer = Vec::with_capacity(size);
unsafe { buffer.set_len(size); }
// Buffer contains uninitialized data, but I'm reading into it immediately
file.read_at(buffer, offset).await;
Is this safe? Yes, with documented invariants:
- The buffer has sufficient capacity (verified before the unsafe block)
- I never read from the buffer before writing to it
- io_uring immediately overwrites the entire buffer
- If you did read before writing, you'd see garbage, not undefined behavior, just garbage
This optimization alone accounts for roughly 40% of the performance improvement over naive allocation. It's not magic; it's just eliminating redundant work.
The Results
With ZeroPool integrated into my checkpoint loader:
200ms → 53ms. A 3.8x speedup.
The allocator was the bottleneck all along. io_uring was ready to move at wire speed. I just needed to get out of its way.
Benchmark Data
Single-threaded allocation and deallocation:
ZeroPool maintains constant ~15ns latency regardless of buffer size—2.6x faster than the bytes crate for large buffers.
Multi-threaded throughput tells the real story:
Near-linear scaling with thread count, and 8.2x faster than sharded-slab under contention at 8 threads. The two-tier design with thread-local shard affinity delivers excellent cache locality while eliminating lock-free data structure complexity.
Design Decisions That Stuck
Thread-Local Cache Size: Too small means frequent shared pool access. Too large means wasteful memory per thread. I use system-aware defaults: 2 buffers for embedded systems, 4 for desktops, 6 for workstations, and 8 for servers.
Power-of-2 Shards: This enables bitwise AND instead of modulo division, faster by orders of magnitude. Plus, you can use get_unchecked() because the mask mathematically guarantees bounds.
LIFO Cache Order: Most recently used buffers are cache-hot in CPU L3. Accessing them first improves cache utilization. This is a small detail that compounds across millions of requests.
First-Fit Over Best-Fit: Best-fit scans the pool to find the smallest suitable buffer. For I/O workloads with predictable buffer sizes, first-fit is O(1) in practice. Simpler and faster.
The API: Designed for Simplicity
use zeropool::BufferPool;
let pool = BufferPool::new(); // System-aware defaults
// Get a buffer
let buffer = pool.get(1024 * 1024);
// Use it for I/O
file.read_at(buffer, offset).await;
// Return it
pool.put(buffer);
No lifetimes, no generics, no configuration complexity unless you want it.
Advanced: Memory Pinning for Latency-Critical Workloads
For ultra-low-latency systems, pin buffers in RAM to prevent OS swapping:
let pool = BufferPool::builder()
.pinned_memory(true) // Uses `mlock()`
.build();
This prevents buffer memory from being swapped to disk, ensuring consistent latency. Useful for high-frequency trading systems, real-time audio/video processing, and security-sensitive workloads where swap leakage is a concern.
What This Experience Taught Me
Profile first, optimize second: I assumed io_uring was the bottleneck. Profiling showed the allocator was. Measurement beats intuition every single time.
Existing libraries aren't always the answer: Sometimes the 80% solution doesn't cover your 20%. Building from scratch isn't failure; it's pragmatism when the problem space is well-defined and your requirements are clear.
Unsafe code is a tool with documentation requirements: Rust's safety guarantees are remarkable, but sometimes you step outside them. The key is rigorously documenting your safety invariants so future maintainers (or you, six months from now) understand exactly why the unsafe code is sound.
Thread-local storage is underrated: Lock-free data structures are genuinely hard to build correctly. Thread-local storage gives you lock-free behavior for free within a single thread. Use it aggressively.
Power-of-2 everything: If your size or count can be a power of 2, make it one. You unlock bitwise operations, cache alignment, and compiler optimizations that simply aren't available otherwise.
Try It Yourself
ZeroPool is on crates.io:
cargo add zeropool
Source: github.com/botirk38/zeropool
Run the benchmarks yourself:
git clone https://github.com/botirk38/zeropool
cd zeropool
cargo bench
What's Next
Ideas in exploration:
- Async
get()API for backpressure control when pool exhaustion occurs - Size-class buckets to maintain separate pools for different buffer ranges
- NUMA awareness for multi-socket systems
- Custom allocator support (jemalloc, mimalloc)
For now, ZeroPool does exactly one thing: get out of the way and let io_uring fly.
Have you encountered similar performance walls? Found this approach useful? Reach out on Twitter or GitHub, I'd love to hear about what you're building.